英文题目:Long-read sequencing reveals the complex splicing profile of the psychiatric risk gene CACNA1C in human brain
发表杂志:Mol. Psychiatry,2020年1月
影响因子:11.973
研究背景
在人脑中,与精神分裂症相关的基因组区域富集了在神经发育过程中表现出不同异构体使用的基因,RNA剪接是将遗传变异与精神疾病联系起来的关键机制。剪接图谱在大脑中特别多样,很难准确识别和量化。短读长RNA-Seq方法不能准确地重建和定量大多数转录物和蛋白质异构体,为解决这一挑战,本文将long-range PCR和nanopore全长转录组测序与一种新的生信分析流程结合。
CACNA1C是一种精神危险基因,编码电压门控钙通道CaV1.2,CACNA1C基因很大而且很复杂,至少有50个注释外显子和31个预测的转录本。它的大小和复杂性使得用标准的基因表达方法准确鉴定和量化转录本变得极其困难,本文在人脑中鉴定了CACNA1C的全长编码转录本,识别了38个新的外显子和241个新的转录本,对异构体多样性的详细了解对于将精神病学基因组发现转化为病理生理学见解和新的精神药理靶点至关重要。
研究方法
样本:来自利伯脑发育研究所储存库的三名成年捐赠者的尸检脑组织(提取小脑、纹状体、背外侧前额叶皮质、扣带回、枕叶和顶叶皮质的RNA,并进行逆转录)
测序方法:使用PCR扩增CACNA1C全长CDS,使用MinION进行测序
分析流程:https://github.com/twrze/TAQLoRe
研究结果
1、CACNA1C有很多外显子和异构体
由于CACNA1C的复杂性,本文使用了两种互补的方法来鉴定转录本:外显子水平和剪接位点水平的分析,分析流程见补充图2。该方法共鉴定了251种存在于人脑中独特的CACNA1C转录异构体,其中241种是新的,包括使用新的外显子,新的剪接位点和连接。

补充图2
在CACNA1C基因座内总共注释了39个潜在的新外显子,其中38个在至少2个人或组织中被识别,并在每个文库中得到至少5条nanopore reads的支持(图2A)。通过PCR和Sanger测序确认了新的外显子与其周围的注释外显子之间的剪接连接,从而验证了四个新的外显子。这种新的外显子的成功验证提供了很高的可信度,即通过纳米孔测序鉴定的新的外显子是真实的,并且被整合到CACNA1C转录本中。表达量最高的10条转录本中,有9条是新的且其中有8条被预测保持CACNA1C阅读框架,这表明这些最丰富的新转录本中有一些编码功能不同的蛋白质异构体(图2B,C)。这些结果表明,新的CACNA1C转录本表达丰富,数量也很多,目前的注释缺少许多最丰富的CACNA1C转录本。
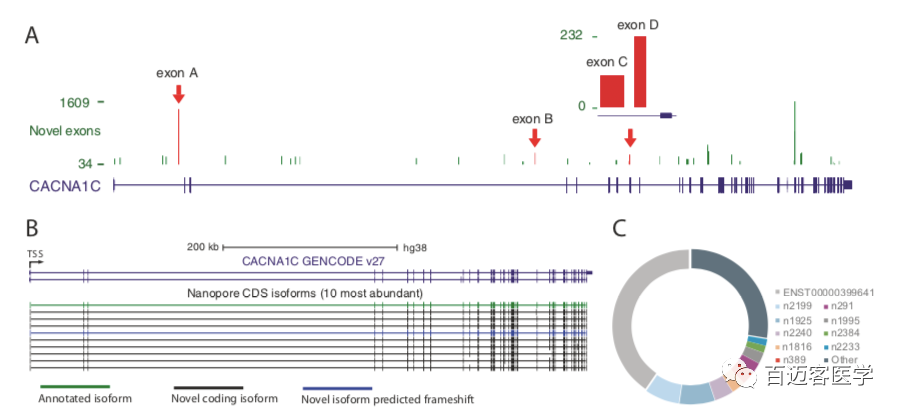
图2
通过设置转录本的高置信度,在6个大脑区域确定了90个高可信的CACNA1C转录本,包括7个先前注释的(GENCODE V27)和83个新的(补充图3)。7个新的高置信度转录本包含新的外显子,而其余76个包含以前未描述的连接和连接组合。
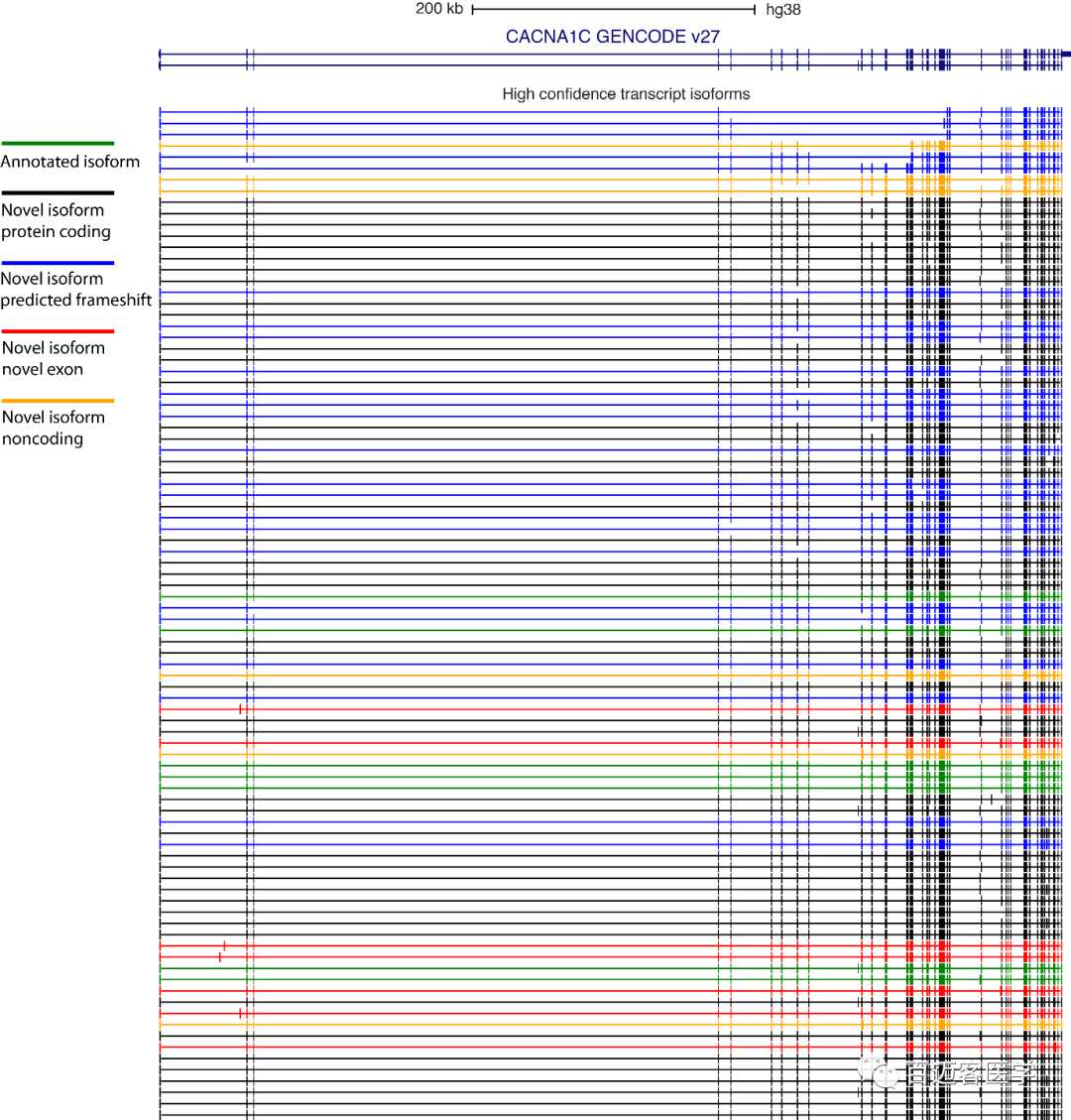
补充图3
上述外显子水平的转录本鉴定方法为鉴定新的外显子和表征全长转录本结构提供了稳健和保守的手段。使用了更为保守的依赖于连接处无错误映射所支持的连接的识别,以及规范剪接位点的方法,确定了497个新的剪接位点,其中393个由至少10条reads支持,这些剪接位点,在筛选了至少24条reads支持的转录本后,鉴定了195个转录本,其中111个被预测为编码的。
2、CACNA1C亚型在不同脑区的表达谱不同
小脑、纹状体与皮质等组织观察到了CACNA1C转录本差异,但在不同个体之间的表达是相似的。在小脑中观察到了明显的转录本表达转换;在小脑之外,ENST00000399641是主要的转录本,而在小脑中,ENST00000399641和CACNA1C n2199的表达水平相似。
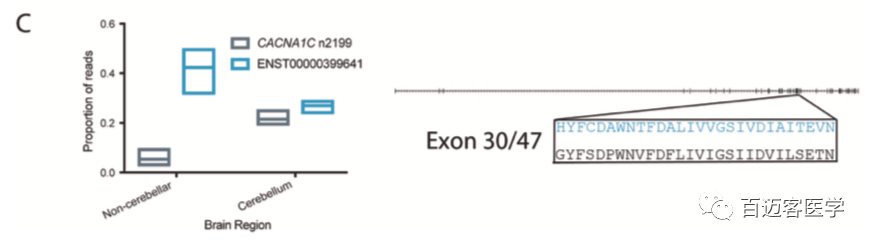
图3 C
3、预测新isoforms对CaV1.2蛋白模型的影响
CACNA1C编码CaV1.2 的主要成孔亚基。钙孔由24个跨膜重复序列组成,由细胞内环连接成4个结构域(I-IV)(图4A)。在我们鉴定的83个新的外显子水平的转录本中,51个可能编码功能性的CaV1.2通道。灰色方框表示新的、框架内的插入和删除的位置(值表示包含每个isoforms的reads的平均比例)。使用两种分析方法(外显子水平和剪切连接水平)鉴定变体的情况,外显子水平计数用于得出丰度(红色文本);仅使用剪接位点水平方法鉴定的变体用蓝色文本表示。包含三个微缺失的蛋白质异构体的数量:(I)在I-II接头中,(Ii)在IV4-5接头中,以及(Iii)在IV3-4接头中先前报道的微缺失(图4B)。
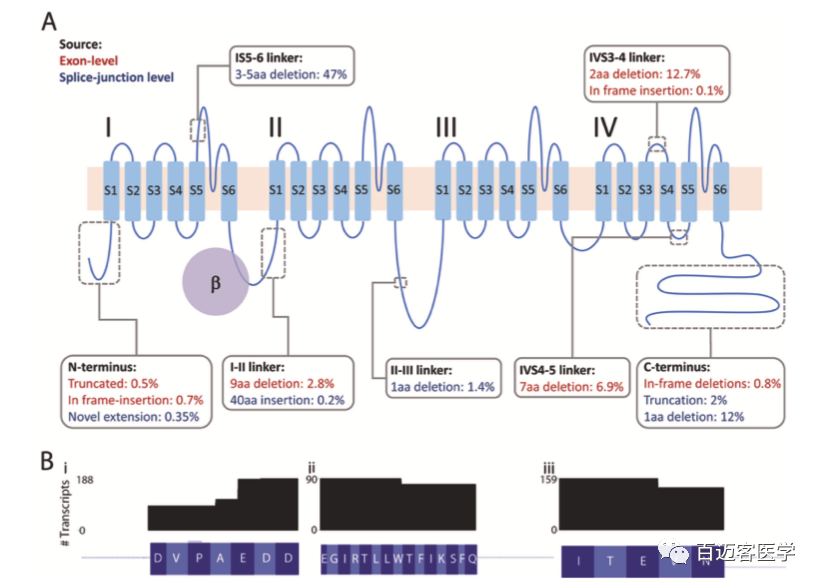
图4
总结
长读长测序技术的快速发展为准确获得转录多样性提供了可能,因为每一条read都包含一个完整的转录本。这对于具有复杂模型的基因尤其重要。由于CACNA1C剪接产生的CaV1.2蛋白对现有的钙通道阻滞剂表现出不同的敏感性,因此有可能选择性地针对疾病相关的CACNA1C亚型和/或那些在大脑与外周差异表达的CACNA1C亚型,提供既更有效又更无外周副作用的新型精神药物。综上,这些观察结果证明了ONT长读长测序对于准确描述转录本结构和选择性剪接的重要性。
参考文献:
Clark Michael B,Wrzesinski Tomasz,Garcia Aintzane B et al. Long-read sequencing reveals the complex splicing profile of the psychiatric risk gene CACNA1C in human brain.[J] .Mol. Psychiatry, 2020, 25: 37-47.

]]>

研究背景
随着农业面积的减少和人口的增长,粮食危机正成为一个日益严重的问题。沙漠约占地球陆地表面积的三分之一,是贫瘠的环境,几乎没有降水,通常有干燥和碱性土壤,因此对大多数植物和动物的生活条件都很不利。然而,一些沙漠地区仍可以种植一些作物。洞察这些物种的环境适应和经济特征,有助于在不同的沙漠地区种植和繁殖这些作物,这可能有助于缓解世界粮食危机。
开心果(p.vera,2n=30,图1a)双子叶植物纲、无患子目和漆树科,是起源于中亚和中东的腰果家族成员。它是一种沙漠植物,对盐渍土有很高的耐性。开心果最近成为第五大坚果作物,除了具有经济、营养和药用价值外,对非生物胁迫也有很强的适应能力,被认为是一种能耐受干旱和盐碱胁迫的物种,是干旱和盐碱区重新造林的理想选择。
尽管基因组测序的快速发展有助于发现许多作物驯化和改良的遗传基础,但关于开心果的研究却很少。据估计,开心果的基因组大小约为600 MB,杂合率高。Moazzzam Jazi等人利用全基因组转录组,通过对照和盐处理两个开心果品种的比较,发现了耐盐性相关的标记物和应激反应机制。
在本研究中,为了更好地了解开心果驯化的分子进化历史,研究人员组装了开心果的基因组草图,并对107个全基因组进行了重测序,包括93个驯化和14个野生的开心果以及35个不同野生黄连木属物种。整合基因组和转录组学分析显示,扩张的基因家族(如细胞色素P450和几丁质酶)和茉莉酸(JA)生物合成途径可能参与应激适应。比较群体基因组分析显示,开心果大约在8000年前被驯化,驯化的关键基因可能是那些涉及树木和种子大小的基因,这些基因经历了人工选择。这些基因组序列应该有助于未来的研究,以了解沙漠作物的农业和环境相关特性的遗传基础。
材料方法
开心果(P.vera)二代测序denovo:
测序材料:开心果栽培种“Batoury”;Illumina Hiseq 2500[包括两种类型小片段文库(270 bp和500 bp)]和六种类型 mate-pair文库(3 kb、4 kb、8 kb、10 kb、15 kb和17 kb);PacBio sequel
重测序:107个开心果(93个驯化+14个野生)、35个不同野生黄连木属物种;Illumina;
转录组:A:盐处理:Ohadi(根:salt treatment 3 rep vs control 3 rep;叶:salt treatment 3 rep vs control 3 rep);B:野生型和驯化型:Ohadi和Sarakhs[根:Sarakhs (wild 3 rep) vs Ohadi (control 3 rep);叶:Sarakhs (wild 3 rep) vs Ohadi (control 3 rep)];
注:Ohadi与Sarakhs分别代表Pistacia vera的不同品系,Ohadi被认为是驯化型,Sarakhs是野生型)。
研究结果
1.?开心果的基因组进化
利用Illumina Hiseq 2500平台组装了569.12 Mb的开心果基因组草图,Contig N50为20.69kb和Scaffold N50为768.39 Kb。为了提高连续性,进一步通过PacBio sequel系统组装了671 MB的基因组草图,ContigN50为75.7 Kb,Scaffold N50为949.2 Kb。基因组质量与先前报道的植物基因组相一致,有助于一些令人信服的数据分析。装配尺寸略大于估计的基因组尺寸,这可能是与开心果的高杂合度(1.72%)有关。转座因子占开心果基因组的70.7%,其中46.75%为LTR(长末端重复转座)。CEGMA分析表明,96.94%的核心蛋白编码基因被恢复。BUSCO评估表明有94.51%完整的基因模型。
作者首先进行了比较基因组研究,以评估该物种的古历史。利用9个植物基因组单拷贝家族基因的系统基因组分析表明,开心果在58百万年前从柑橘中分离并在105百万年前从毛果杨中分离出来。4DTV结果表明,开心果基因组在其与这些物种的分化之后没有经历谱系特异性的全基因组复制。文中还通过将开心果基因组与基础被子植物无油樟基因组进行共线性分析,表明每个无油樟区域最多有三个开心果区域,而每个开心果区域最多有两个毛果杨区域(图1b)。共线性分析支持这样一个结论:开心果中没有发生谱系特异性基因组复制,但它们与真双子叶植物中发生的γ复制相同,而毛果杨经历了谱系特异性基因组复制事件。
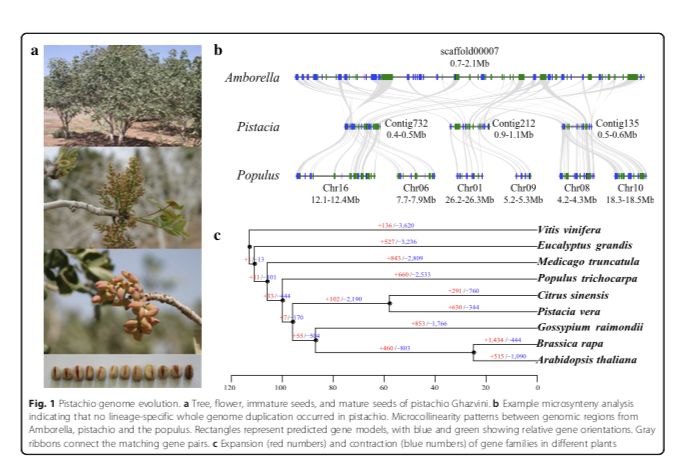
图1 开心果基因组进化
2.?开心果应激适应相关的扩张基因家族
为了揭示开心果表型(如耐盐性)的遗传基础,利用OrthoMCL通过识别不同植物之间独特和共同的基因家族来研究基因家族的进化。开心果与拟南芥、柑橘、雷蒙德氏棉、葡萄相比有9735个共有基因家族,而含有1381个基因的707个开心果有特基因家族。对这些基因进行GO与KEGG富集分析,并都发现了许多与“防御反应”有关的基因,其中包括许多包含NB-ARC domain和NBS-LRR domain的基因。这种基因以植物抗病性著称,对开心果的防御反应具有相当重要的意义。
接下来,作者研究了开心果基因家族的扩张和收缩(图1c)。由于很难从基因家族规模的收缩或与未在该参考基因组中成功组装的基因有关,这里只分析了扩展的基因家族。对扩展基因家族的基因富集分析发现,它们在代谢类别中丰富,如萜类、黄酮类、倍半萜类和生物碱的生物合成。基因家族的扩展发生在长期进化之后,并推动了黄连木属和柑橘属之间的进化差异,而不是开心果从野外驯化的非常短期的进化。因此,我们认为上述基因的扩展可能与野生黄连木中有机化合物的代谢有关。野生黄连木的植物化学筛选发现了许多植物化学物质,如生物碱、黄酮、香豆素、甾醇、单宁、萜类和倍半萜类。
此外,丰富的术语“氧化还原过程”包含许多细胞色素P450基因,这些基因编码参与多种功能复杂代谢途径的蛋白质,并在多个过程中发挥重要作用,特别是在应激反应中发挥作用。在187个细胞色素P450基因中,我们发现许多可能具有耐盐功能。例如,透水性研究发现,CYP94家族基因表达水平的升高可减轻水稻的茉莉酸反应,增强水稻的耐盐性。在开心果的这些扩张基因家族中,有14个CYP94基因。大豆中,CYP82A3参与茉莉酸和乙烯信号通路,增强对盐碱和干旱的抗性,开心果扩张基因家族中有20个CYP82基因成员。毛果杨CYP714A3的异位表达增强了水稻的耐盐性,开心果扩张基因家族中有10个CYP714A基因。因此,一些细胞色素P450基因可能与开心果的耐盐性有关。
3.?RNA-seq揭示了开心果盐适应的遗传机制
进一步研究开心果的耐盐性潜在遗传机制,研究者进行了盐度实验。开心果砧木(P.vera?L.cv.Ohadi)的叶和根在正常条件和盐度条件下进行RNA测序。使用Tophat-Cufflinks-Cuffdiff?pipeline,在盐水条件下处理的植物与对照之间表现出差异表达,鉴定214和461蛋白质编码基因分别在叶和根组织中(ncontrol = 3, nsalinity = 3, corrected P < 0.05,)。基因富集分析发现许多差异表达基因(31个基因)参与到“氧化还原进程”中(图2a,b)。像比较基因组分析一样,该类别中的15个基因是细胞色素P450基因,特别是CYP74A(即AOS),其编码细胞色素P450 CYP74基因家族的一个成员,其起到丙二烯氧化物合酶(AOS)的作用。这种酶催化茉莉酸酯合成中的第一步[即茉莉酸(JA)]。AOS中每千碱基外显子的表达片段(FPKM)值在叶片中从对照中的近0增加到盐水条件下的2163.75,在根中从对照中的1.87增加到盐水处理的87.74。研究者还发现了7个差异表达的基因(ChiC, TT4, ILL6, MYB108, MYB6, PRB1, and TIFY5A)被富集到“茉莉酸反应”中。以前的研究表明,干旱和高盐度导致水稻叶片和根部JA含量增加。盐度处理可以增加湿地物种鸢尾(Iris hexagona)中的内源JA水平。茉莉酸酯激活植物对生物胁迫(即病原体攻击)和非生物胁迫(即盐)的反应。在此,用盐水处理增加了在叶和根中参与茉莉酸反应的这些基因的表达水平(图2c)。这些基因的表达增加(例如,AOS作为酶催化茉莉酸酯合成中的第一步)应该增加茉莉酮酸酯的合成,因此,它们很可能被开心果用于应对盐胁迫。
差异表达的基因富集到“几丁质结合”,其中四种基因编码几丁质酶(CHIB, EP3, ChiC, AT2G43590)。植物几丁质酶涉及多种生物系统。植物中的一些几丁质酶是针对环境胁迫(如高盐浓度,寒冷和干旱)而表达的,并且可以通过植物激素如乙烯,茉莉酸和水杨酸来上调。例如,基因ChiC编码V类几丁质酶,其表达可由茉莉酸和拟南芥盐度引起的胁迫来诱导。研究者的转录组学分析表明,编码几丁质酶的基因和参与JA生物合成途径的基因可能有助于开心果适应盐水环境。
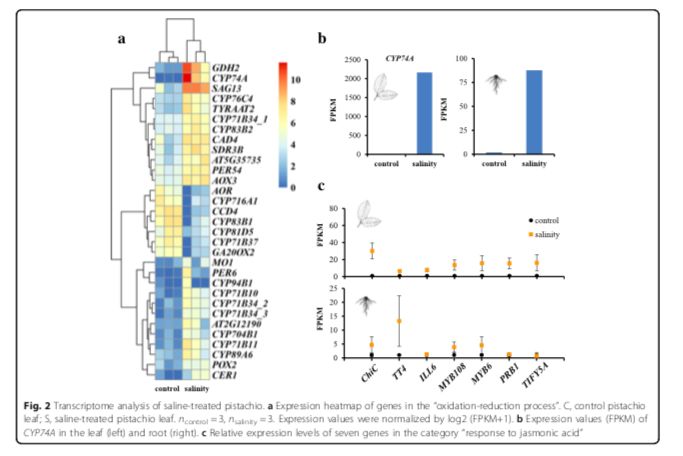
?图2 盐处理下开心果的转录组数据分析
4.?不同野生种间混和
为了研究开心果的种群历史和适应性进化,研究者对107个开心果基因组进行重测序,包括93个品种和14个野生开心果,平均测序深度为6-8X。作者还重新测序了来自不同近缘种的35个基因组,包括P.mutica,P.khinjuk,P.integerrima和P. palaestina。用stringent GATK pipeline,发现14.77百万个单基因变异位点,其中2.42百万个在基因区。使用邻近法和最大似然法的系统发育分析清楚地分离了5种不同的种群,即?P.vera, P.mutica, P. khinjuk, P. integerrima, and P. palaestina。通过TreeMix程序在一些物种之间检测到渐渗的信号,这表明杂交可能在自然界中的不同近亲之间发生,并且与植物中被发现的普遍杂交一致。然而,从其他开心果物种到驯化的开心果没有检测到渐渗,这种现象来源于野生的P. vera(图3)。
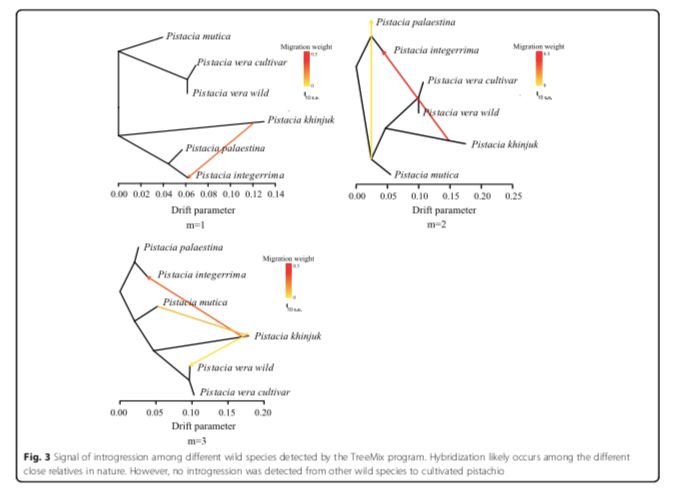
?图3 不同野生种间的基因渐渗
5.?开心果两步驯化历程
基于重测序数据,研究人员推测了这些物种的有效群体大小的变化,并发现在 Pleistocene期间发生了瓶颈事件,且在 ~200 kyr前,有效群体大小增加。系统发育树显示驯化和野生开心果之间的分离(图4a)。利用δaδi推算野生和驯化开心果的分化时间在 ~8000年前,这与早在公元前6750年就表明开心果种子是一种常见的食物这一考古记录相似。为了深入了解开心果种质之间的遗传关系,研究人员进行了两项经典分析:群体结构和主成分分析(图4b,c)。这些分析清晰的显示栽培种质分为两个群。栽培种Group I的LD最高,栽培种Group II和野生开心果的LD衰减值相近。Group II包括 Qazvini,Italiaei和Badami
Zarand在内的5种类型的个体,且这些种质被记录为古代具有种子的材料(图4d)。与系统发育树一致,这三个品种含有较高比例的野生血统(图4e),这些结果支持了其两步驯化的过程,初步驯化,然后通过作物育种进行改良。
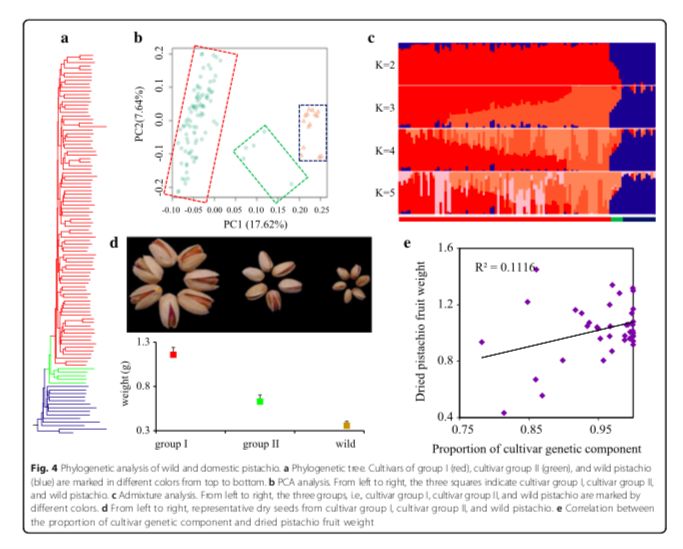
图4 野生和驯化开心果的系统发育关系分析
6.?开心果驯化的遗传机制
群体核苷酸多态性θπ分析揭示了驯化型种质的核苷酸多态性低于野生型种质,通过分析发现,栽培种质中基因组上的一些区域的多态性降低,这些区域可能含有受到人工选择的基因。此外,研究人员鉴定了栽培型和野生型样品分化水平增加的区域。在驯化和野生的开心果之间,在基因组上约有9.2 Mb的区域被鉴定为具有高水平的群体分化。栽培种间遗传多样性降低,且超过95%的阈值。遗传多样性减少的区域和群体分化增强的区域在驯化或育种过程中经历了选择性清除。共计有665个基因定位在该区域。研究人员定位了受正向选择的候选基因,其可能与驯化过程中重要的表型进化相关。在开心果驯化的过程中,其树形大小经历了人工选择(图5a)。研究人员发现了基因SAUR55(图5b),编码生长素应激蛋白,在植物的生长过程中发挥重要的作用,其在开心果的人工选择下进化而来。除此之外,基于也和根的转录组数据分析结果显示,驯化种与野生种相比,基因SAUR55表现出了显著增加的表达水平(图5c)。这些结果与在其它作物(如水稻和小麦)中生长素应激性基因的选择性清除的研究结果一致,并揭示了在作物驯化期间类似特征性状的人工选择。果实重量是作物驯化和育种期间最重要的特征之一,包括开心果。在栽培种中,品种成分与果实重量呈正相关(图4e)。这支持了一个结论,在开心果中,果实重量的人工选择发生在驯化与人工选择期间。研究人员指出,基因CYCD7-1在人工选择的进化下,野生种和驯化的栽培种之间具有高度的群体分化特征。该基因编码D型细胞周期蛋白,控制细胞分裂及种子发育过程中的生长率。CYCD7-1基因的过表达包括在胚胎和胚乳中的细胞增殖和细胞增大,其在拟南芥中导致种子过度生长。基因CYCD7-1在花粉和早期发育中显示特殊表达,但在叶和根中没有表达。因此,有希望在未来的实验中比较野生型和驯化型开心果在花粉和早起发育时期CYCD7-1基因的表达,研究人员提出在CYCD7-1基因上进行的人工选择可能会改变开心果的重量。
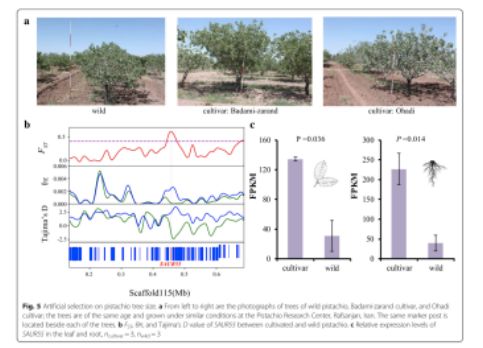
?图5 开心果果树大小的人工选择
结论
本研究为开心果的局部适应和驯化提供了遗传学基础。黄连木属物种基因组序列有助于未来的研究,以了解沙漠作物农艺和环境相关性状的遗传基础。
如果您的科研项目有问题,欢迎点击下方按钮咨询我们,我们将免费为您设计文章方案。

影响因子:8.827
文章题目:The Tartary Buckwheat Genome Provides Insights into Rutin Biosynthesis and Abiotic Stress Tolerance
摘要概述
A high-quality, chromosome-scale Tartary buckwheat genome sequence of 489.3 Mb is assembled. A new buckwheat lineage-specific whole genome duplication is discovered. The reference genome facilitated the identification of many new genes predicted to be involved in rutin biosynthesis and regulation,aluminum stress resistance, and in drought and cold stress responses.
研究背景
苦荞也叫苦荞麦(Fagopyrum tataricum)是蓼科荞麦属作物,虽然我们习惯认为它属于麦类,但其实他并非禾本科而是蓼科。苦荞性喜阴湿冷凉,多种植于高山地域,一般垂直分布为海拔1200~3500m。所以苦荞具有很高的抗逆性,尤其是在抗寒和抗干旱方面。苦荞是药食两用的作物,苦荞麦性味苦、平、寒, 有益气力、续精神、利耳目、降气宽肠健胃的作用。能降血压、降血糖、降血脂, 改善微循环等作用, 又称“三降”食品。其主要药用成分为芦丁,该文章也对芦丁的生物合成进行了研究。
测序材料
鞑靼荞麦(Fagopyrum tataricum cv. Pinku1),2n=2X=16;
测序方法
Illumina、BioNano、PacBio、Hi-C、fosmid
研究内容
1.基因组组装和注释
苦荞通过K-mer预估基因组大小约为489Mb,流式细胞仪预估为540Mb。共组装出来489.3Mb的基因组序列,共8778个Contigs,Contig N50=550.7kb。通过Hi-C数据将436.4Mb的序列锚定到8条染色体上(定位比例为89.18%)。然后再通过光学图谱数据进行校正。三代数据的准确性通过二代评估为99.96%,并且在基因区具有更少的错误存在。
共预测得到33366个基因,平均每100Kb具有6.8个基因。非编码RNA注释结果为278 miRNAs, 1,395 tRNAs, 455 rRNAs, and 518 snRNAs。通过注释已组装基因组的50.96%为重复序列,其中LTR的比例占全基因组的38.64,包含Gypsy (30.52%) 和 Copia (5.48%)。
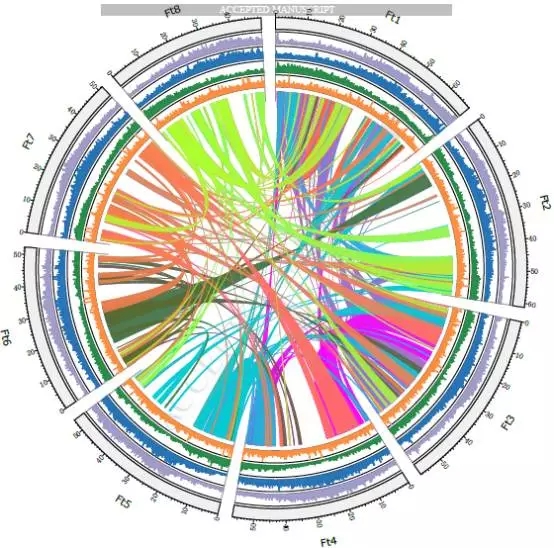
图1 苦荞基因组circle图
2.系统发育和全基因组复制事件分析
苦荞与拟南芥、可可、大豆、葡萄、杨树、马铃薯、番茄以及单子叶的水稻和玉米构建系统发育进化树,见下图。此外还进行基因家族聚类分析,找出共同和特有的基因家族。
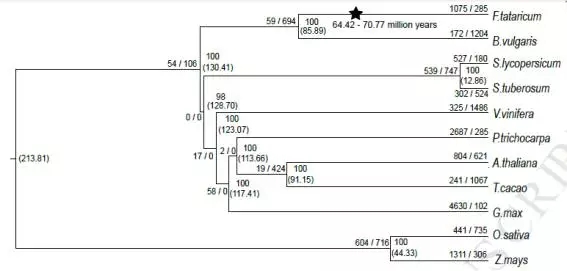
图2 苦荞系统发育进化树
通过苦荞与拟南芥、苦荞与甜菜进行分析,通过Ks计算发现苦荞经历了全基因组复制事件,近期是在下图0.84-0.92之间,而更古老的一次复制发现在64.42~70.77 Mya。而全基因组复制事件的发生,也导致了很多与抗逆相关基因家族的扩张或者保留。这也与后期苦荞的抗逆性有一定关系。
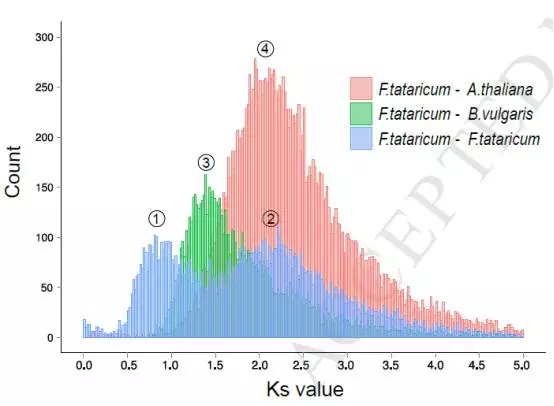
图3 苦荞全基因组复制事件
3.参与芦丁合成基因的鉴定
芦丁的生物合成具有特殊的意义,而苦荞被认为是这种有益的类黄酮的主要食物来源。苦干荞麦营养生物质中含有3%的芦丁。通过比较基因组以及不同生长部位的转录组测序,发现原来所不知道的全长蛋白CHI(FtPinG0002790600)和f3h(FtPinG0006662600)。
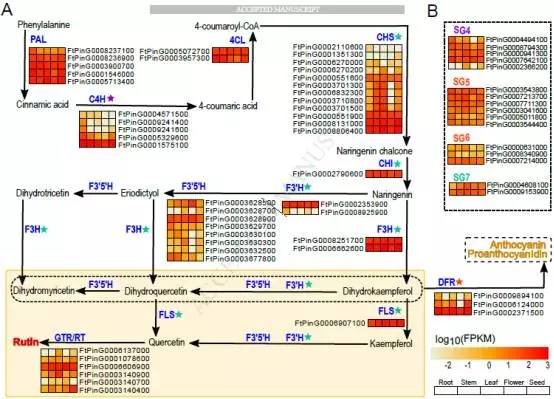
图4 芦丁生物合成途径的研究
4.苦荞抗逆性研究
该研究还发现苦荞中存在大量与植物耐铝、抗旱和耐寒相关的新基因,其中产物包括一些转运蛋白以及相关的转录因子。
小编总结
本文研究了苦荞的基因组测序,除了三代测序还通过光学图谱和Hi-C技术进一步提升基因组的组装质量。通过比较基因组学研究明确了苦荞的系统发育地位,以及通过全基因组复制事件的研究发现了抗逆基因的扩张和保留。其中结合转录组测序对芦丁的生物合成途径进行了研究。
该研究由山西农科院农作物品种资源研究所乔治军研究员团队联合中国科学院遗传与发育生物学研究所梁承志研究员团队及华南农农业大学王俊教授团队共同完成,其中百迈客只参与了其中部分研究,再次祝贺各位老师取得好的成绩。
参考文献
The Tartary buckwheat genome provides insights into rutin biosynthesis and abiotic stress tolerance.
]]>The genome sequence of allopolyploid Brassica juncea and analysis of differential homoeolog gene expression influencing selection.
一 ?研究背景
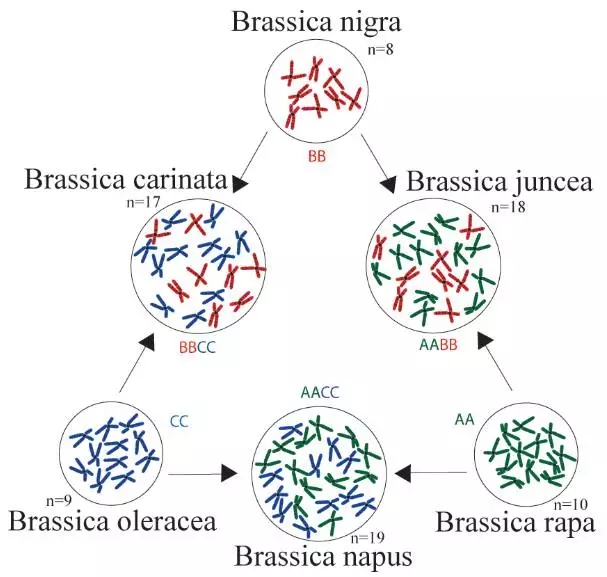
图1.芸薹属禹氏三角(From Wikipedia)
异源四倍体芥菜(AABB)属于十字花科芸薹属,是重要经济作物,主要包括菜用和油用芥菜两大类群,种植范围较广,经济价值较大。菜用芥菜主要分布在中国等东亚国家和地区,油用芥菜主要分布在印度等南亚国家和地区。芥菜是“禹氏三角”中重要的一员,由白菜和黑芥杂交后加倍而来,至少发生了三次古多倍化事件,因此非常具有研究价值。但是由于其为异源多倍体,相关的全基因组测序工作一直很难开展。来自浙江大学、北京百迈客等单位的团队共同合作,利用新的测序技术(PacBio+BioNano),成功的组装出高质量的芥菜基因组图谱,为进一步改良芥菜的农艺性状提供了基础,为多倍体物种遗传育种提供了新的方向。同时,也从多角度论证了芥菜A亚基因组起源问题,揭示了多倍体亚基因组间同源基因表达与选择机制。
二 ?研究方法
1、组装
基于文章设计,我们选取菜用芥菜的一个变种(榨菜),使用二代测序和三代测序相结合的方法进行初步组装,然后利用光学图谱进行校正,得到了一版高质量的芥菜基因组,其中contig N50 由 28Kb 提升到61Kb ,scaffold N50 由710k 提升到1.5Mb.基因组完整性达到85%。另外我们还利用二代测序技术组装了一版黑芥的基因组,基因组大小为591Mb,完整度为68%。
然后利用遗传图和光学图谱对A、B亚基因组进行区分,整体挂载效果非常好,A为91.48%,B为72.32%。利用光学图谱和遗传图谱对基因组进行区分,为其他多倍体物种基因组研究提供了参考。
2、基因组注释情况
在高质量的基因组的情况下,我们采用从头+同源+转录组结合的方法在芥菜基因组中获得了80050个编码蛋白的基因,其中有97.8%的基因可以注释到Nr库。另外黑芥基因组预测出来49826个编码蛋白的基因,其中94.7%可以注释到Nr。重复序列部分芥菜A基因组中重复序列比例为44.25%,B为52.37%。芥菜基因组特征情况见下图:
三 ?研究结果
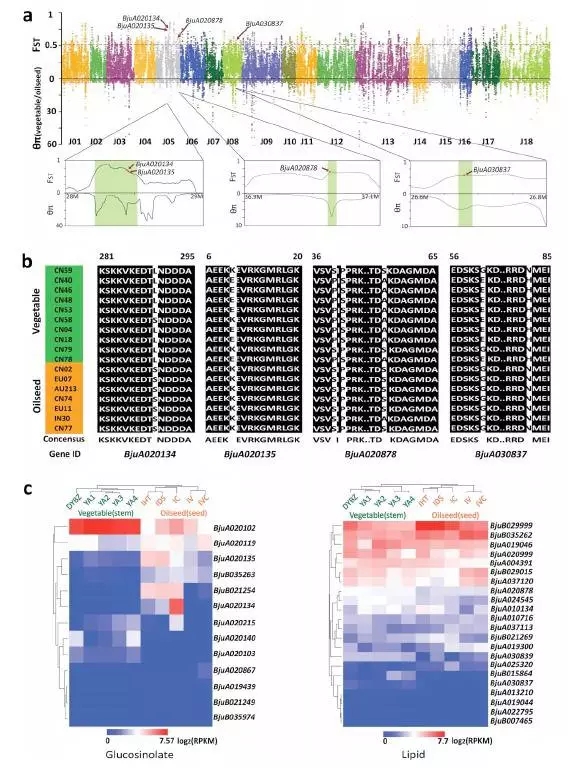
1、芥菜A亚基因组起源问题
芥菜的基因组是异源四倍体(AABB),在“禹氏三角”中由白菜(AA),黑芥(BB)杂交后加倍形成,在演化过程中变异类型非常丰富。问题是油用芥菜的AA和菜用芥菜的AA是来自同一个亚种,还是来自多个亚种呢,这个问题就是A亚基因组的起源问题。
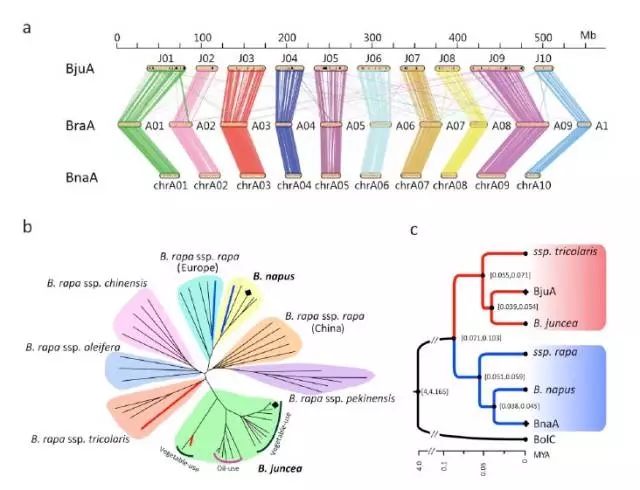
如上图,a中对芥菜A、白菜A、甘蓝型油菜A进行共线性分析,可以发现其是高度共线的。
我们对10个菜用的芥菜、7个油用的芥菜,5个甘蓝型油菜基因组、27个白菜基因组(多亚种)进行了重测序分析,并绘制如上图b中的进化树。从b图中可以看到芥菜全部聚在一起,没有出现分散的情况,说明芥菜中A的基因组是来源于同一个亚种,属于单系起源。
C图中对同源物种和芥菜进行了进化树构建,并计算了芥菜分化的具体时间为3-5万年。
除了从群体的角度研究了芥菜亚基因组A起源问题,还从PCA聚类和Fixed SNP角度验正了单系起源的结论。
2、基因表达的dominance现象
由于芥菜基因组是异源四倍体,也就是说基因组中存在两套非常相似的亚基因组,那么在基因表达的过程中,位于两套亚基因组上的等位基因的表达模式是怎么样的呢,是一起表达,是相互抑制,还是一方占主导?
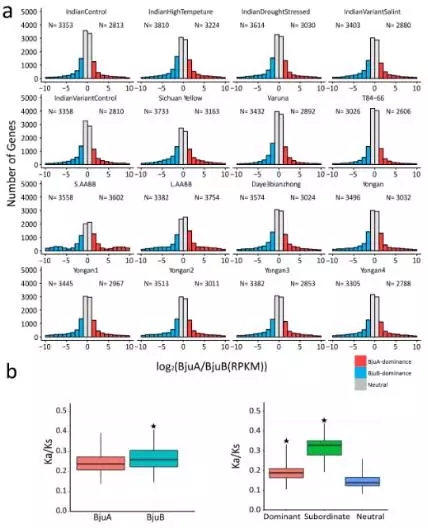
通过计算等位基因的表达量,发现在不同的时期,不同组织之间,发现存在dominance基因,存在dominance的基因经受的选择压力大于Neutral基因(不存在dominance现象,功能非常重要,纯化作用较强,不轻易突变),但是小于Subordinate基因(作用不重要,纯化作用较小,易丢失)。
3、油用芥菜和菜用芥菜的选择与分化
通过菜用和油用芥菜群体进行选择清除分析,发现dominance的基因被筛选出来的比例较高,同时结合转录组数据,这部分基因在油用和菜用两个群体中差异表达。同时通过上面的分析发现与硫苷,脂类代谢显著相关并且存在dominance的基因组,这些基因在油用菜用群体中有各自独特基因分型。
四 ?文章亮点
1. 多倍体复杂基因组解决方案:二代+三代+光学,组装出高质量复杂基因组;
2. 多个角度证据解决芥菜亚基因组A亚基因组单系起源/杂交起源争论:Asubgenome phylogenetic tree,PCA, polymprphism and fixed SNP;
3. 通过构建群体模型及贝叶斯方法评估多倍体芥菜形成时间上下限,为新多倍体物种形成时间估算提供新方法;
4. 从不同发育时期,不同组织,不同处理条件,不同进化时期多个角度系统分析异源多倍体dominance 现象;
5. 通过油用菜用群体选择角度识别vegetable- and oil- use B. juncea 分化选择区域,发现与硫苷,脂类代谢显著相关并且存在dominance的基因组,这些基因在油用菜用群体中有各自独特基因分型;
6. 首次找到dominance gene 与潜在农艺性状选择相关性的证据,为多倍体物种遗传育种提供了新的方向和基因候选材料。
五 ?摘 要
The Brassica genus encompasses three diploid and three allopolyploid genomes, but a clear understanding of the evolution of agriculturally important traits via polyploidy is lacking. We assembled an allopolyploid Brassica juncea genome by shotgun and single-molecule reads integrated to genomic and genetic maps. We discovered that the A subgenomes of B. juncea and Brassica napus each had independent origins. Results suggested that A subgenomes of B. juncea were of monophyletic origin and evolved into vegetable-use and oil-use subvarieties. Homoeolog expression dominance occurs between subgenomes of allopolyploid B. juncea, in which differentially expressed genes display more selection potential than neutral genes. Homoeolog expression dominance in B. juncea has facilitated selection of glucosinolate and lipid metabolism genes in subvarieties used as vegetables and for oil production. These homoeolog expression dominance relationships among Brassicaceae genomes have contributed to selection response, predicting the directional effects of selection in a polyploid crop genome.
六 ?参考文献
[1] The genome sequence of allopolyploid Brassica juncea and analysis of differential homoeolog gene expression influencing selection.
]]>
亚基因组的平行趋同选择是导致芸薹和甘蓝的形态型多样化以及趋同驯化的主要动力
2016年8月15日,《自然-遗传学》(Nature Genetics)杂志在线发表了中国农业科学院蔬菜花卉研究所王晓武研究组和北京百迈客生物科技有限公司合作的研究成果。借助重测序技术以及芸薹属祖先的染色体核型(translocation Proto-Calepineae Karyotype,tPCK),他们对芸薹和甘蓝的形态型的平行和趋同进化现象进行了深入研究,该研究最主要的成果是国际上首次发现全基因组三倍化事件是导致芸薹类物种的形态型多样化以及趋同驯化的原因;此外挖掘出两个重要的商业性状——叶片结球性状和块茎形态性状的重要调控基因,为今后的分子育种工作提供遗传基础。
芸薹属包括三个二倍体物种:芸薹(Brassica rapa)、黑芥(B. nigra)和甘蓝(B. oleracea),这三个基本种经过两两杂交又产生了四倍体的欧洲油菜(B. napus)、非洲油菜(B. carinata)和芥菜(B. juncea),这就是“禹氏三角”。随着人工驯化和持续的育种工作,这些物种产生了高度多样化的形态型,例如结成球状的叶片、膨大的块茎(或根部、顶芽、腋芽等)。有意思的是,某些物种的形态型,尽管是在不同的地区独立培育而成,但却表现出相似的表型特征,这便是趋同驯化的结果。
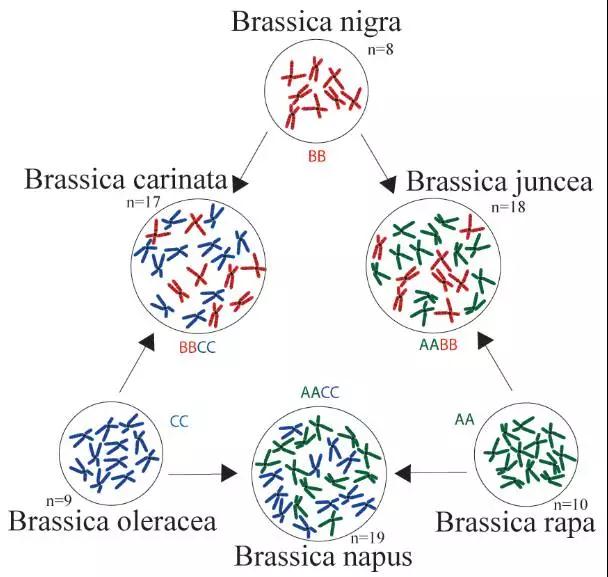
图1.芸薹属禹氏三角(From Wikipedia)
导致芸薹属种内形态型多样化以及种间趋同驯化的机制是什么?这是科学家们一直在探讨的问题。然而芸薹属的起源进化历史也是相当的“波折”——芸薹属的祖先是一个具有7条染色体的二倍体,在约1200万年前发生过一次全基因组三倍化事件,该事件导致一个具有42条染色体的古六倍体物种出现。随后这个六倍体物种的基因组发生了广泛的二倍体化——有时候一条染色体的一段区域转移到另一条染色体上,有时候某个区域会丢失,更有时候连整条染色体都会消失。最终六倍体的又变回了二倍体的“模样”,形成了现在的芸薹属二倍体物种分类格局。——如此复杂的进化历史自然带来不少的阻碍,所幸的是,借助于不断发展的高通量测序技术和生物信息分析方法,科学家们能够从基因组层面解析物种的进化机制成为可能。
在这项研究中,王晓武研究组选择不同形态型的芸薹199株和甘蓝119株作为实验材料,这些材料包括不同地理区域分布的13个芸薹及9个甘蓝亚群,其中涉及叶片结球型(56份大白菜,45份卷心菜),以及块茎膨大型(54份大头菜及19份苤蓝)。应用的是Illumina?Hiseq2000测序平台,350bp插入片段文库,每个个体的平均测序深度均大于8X。
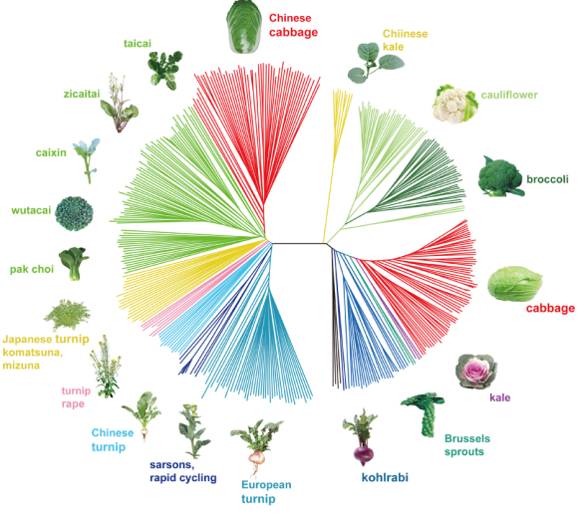
图2. 系统发育树构建
为了调查不同形态的品种的驯化历史,应用两个群体共有的6707个SNP位点构建系统发育树,如图2所示,芸薹可以分成6个组,其中芜菁(turnip)和野油菜(sarsons)等位于系统发育树基部;大白菜(Chinese cabbage)位于最远端,表明驯化历史最短。甘蓝群体可以划分成7个组,其中卷心菜(cabbage)位于最远端。从进化树不难看出,大白菜和卷心菜虽然具有相似的叶片结球特征,却是不同的祖先经过平行或趋同驯化产生的;相类似地,芜菁和苤蓝具有相似的块茎膨大特征,也同样是平行或趋同驯化的结果。
分别对芸薹和甘蓝种内结球和不结球的群体进行分析——主要通过ROD和PiHS两个指数,共同筛选具有正选择信号的基因区域。结果显示芸薹中有20个区域是ROD和PiHS共同定位到的,甘蓝中是18个。进一步对这些区域进行基因注释和富集,发现4个与植物激素应答相关的GO类别,这些植物激素对叶片形状和极性非常重要;此外还发现影响叶片弧度的一些基因同样受到正选择。
进一步检测古六倍体的亚基因组对芸薹和甘蓝结球性状的平行或趋同进化的影响,作者将两个物种的基因组打碎成基因单元,再根据已知的祖先染色体核型,将上述基因单元重排和串接,分别构建出芸薹的三个亚基因组一致序列和甘蓝的三个亚基因组一致序列。重新进行PiHS分析后,发现芸薹的不同亚基因组之间存在4个平行选择信号的区域,甘蓝存在4个;同时芸薹和甘蓝的相同亚基因组之间存在着15个受到趋同选择的区域。
随后针对块茎膨大性状进行的研究亦获得了类似的结果。由此证明,芸薹族祖先的全基因组三倍化事件可能对芸薹属性状平行或趋同进化的造成深远的影响,这一发现在国际上尚属首次。

图3. ?芸薹(左)和甘蓝(右)亚基因组的选择信号检测
参考文献
ChengF.?et?al.?(2016).?“Subgenome?parallel?selection?is?associated?with?morphotype?diversification?and?convergent?crop?domestication?in?Brassica?rapa?and?Brassica?oleracea.”?Nat?Genet?advance?online?publication.
]]>